


浏览器访问https://reading.smartedu.cn/youth,打开控制台发现https://s-file-1.ykt.cbern.com.cn/reading/api/zh-CN/14fba334-5e8b-4523-8b60-1f3abde6f60c/elearning_library/v1/libraries/42b4e538-7319-47cb-9d10-12fb58b78420/contents/actions/full/adapter/f848d8b521af3a6c13474ae97d117e7f428208b77884aa2dd46599d81a4ae1a5/files/0.json中包含了所有的读本信息,共计341本。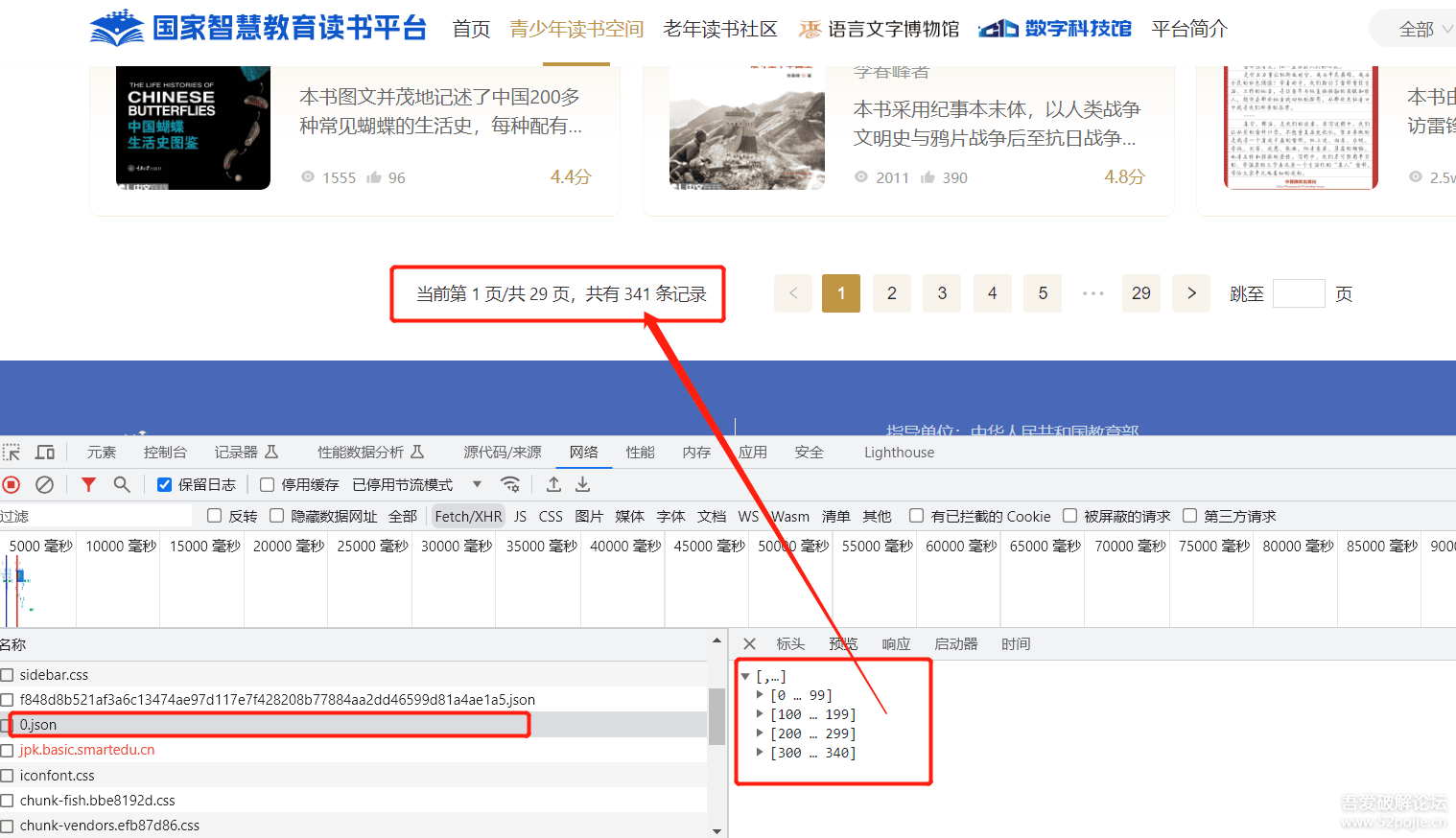
随便点击某个电子书条目,发现浏览器会请求访问 https://s-file-1.ykt.cbern.com.cn/reading/api_static/smart_ebooks/8be1d5a8-1df4-4279-aba8-b1fe2f4f2810.json 地址,不难发现只需要拼接上第一步中0.json中的unit_id即可。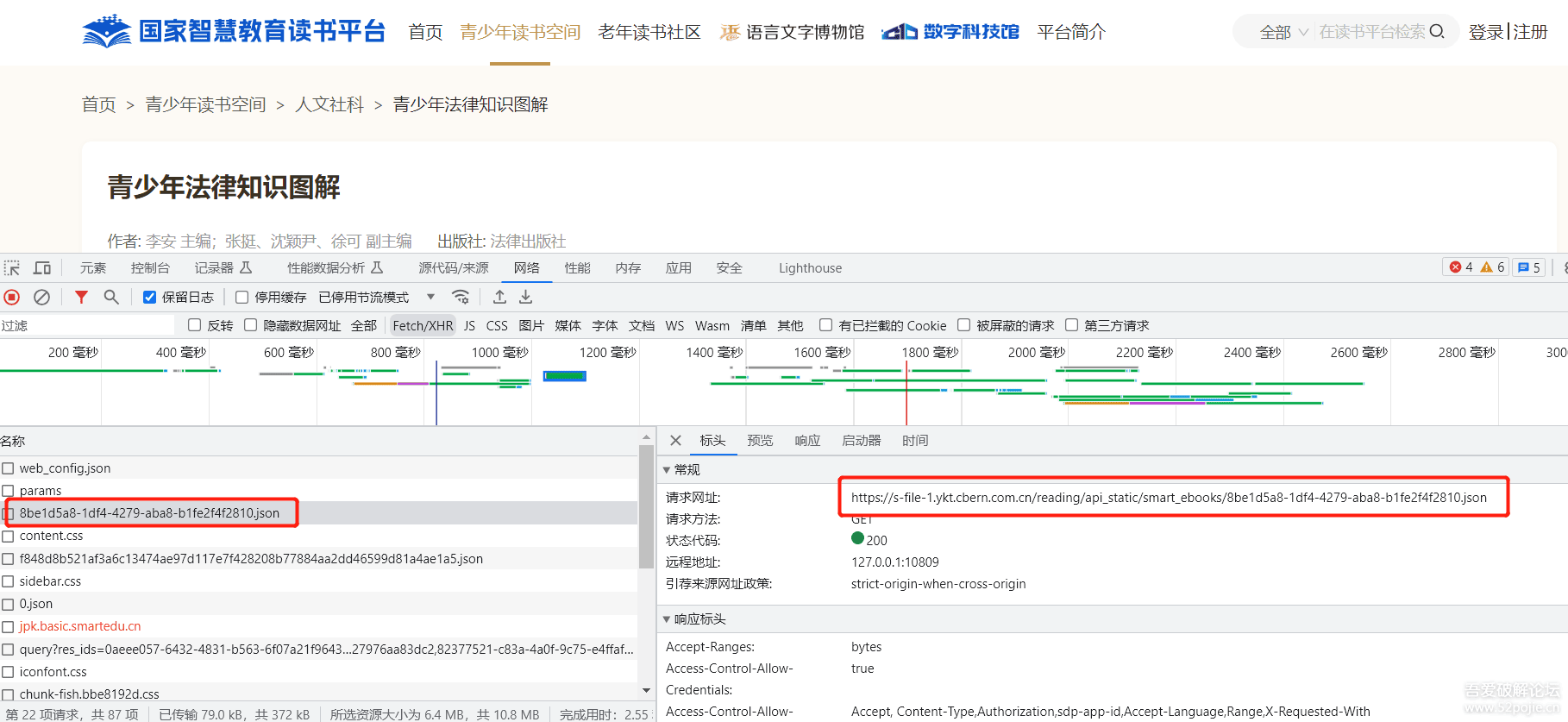
观察以上请求地址返回的json内容,发现ebook_third_file即为完整的电子书访问路径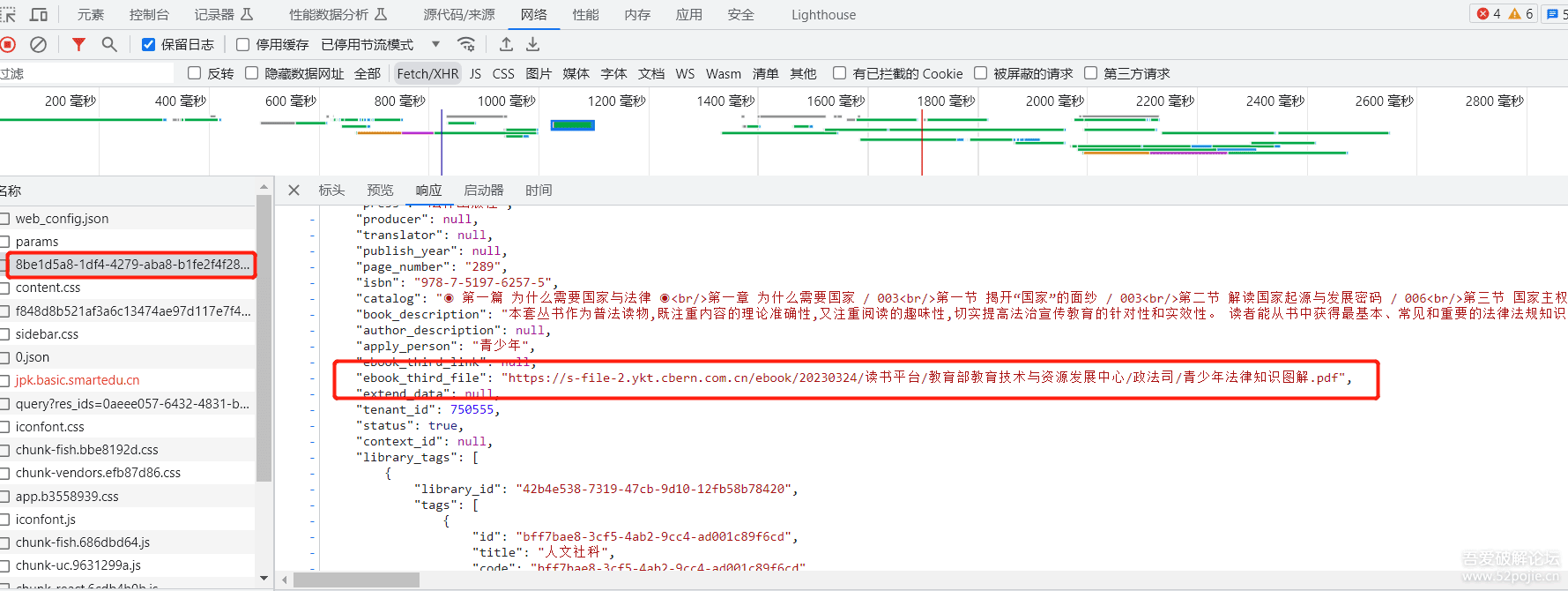
因此接下来思路很简单。
直接上代码
import requests
import os
from concurrent.futures import ThreadPoolExecutor
# 青少年读本文件列表
url = 'https://s-file-1.ykt.cbern.com.cn/reading/api/zh-CN/14fba334-5e8b-4523-8b60-1f3abde6f60c/elearning_library/v1/libraries/42b4e538-7319-47cb-9d10-12fb58b78420/contents/actions/full/adapter/f848d8b521af3a6c13474ae97d117e7f428208b77884aa2dd46599d81a4ae1a5/files/0.json'
# 下载目录
download_dir = './ebooks'
# 下载集合
download_lists = []
def download_list():
response = requests.get(url).json()
for item in response:
# 拼接文件访问地址
file_url = f"https://s-file-1.ykt.cbern.com.cn/reading/api_static/smart_ebooks/{item['unit_id']}.json"
# 获取文件真实下载链接
download_url = requests.get(file_url).json()['ebook_third_file']
# 拼接文件完整保存路径
output = f"{download_dir}/{item['tags'][0]['title']}/{item['title']}.pdf".replace(' ', '')
.replace(':', '·').replace(':', '·').replace("“", "").replace("”", "")
# 添加到下载集合
download_lists.append((download_url, output))
def download(download_url, output):
# 获取文件目录
file_download_dir = os.path.dirname(output)
# 判断目录是否存在,不存在则创建
if not os.path.exists(file_download_dir):
os.makedirs(file_download_dir)
# 下载文件
resp = requests.get(download_url)
# 保存文件
with open(output, 'wb') as f:
f.write(resp.content)
print(f"下载完成:{output}")
if __name__ == '__main__':
download_list()
# 多线程下载
with ThreadPoolExecutor(max_workers=10) as executor:
for arg in download_lists:
executor.submit(download, *arg)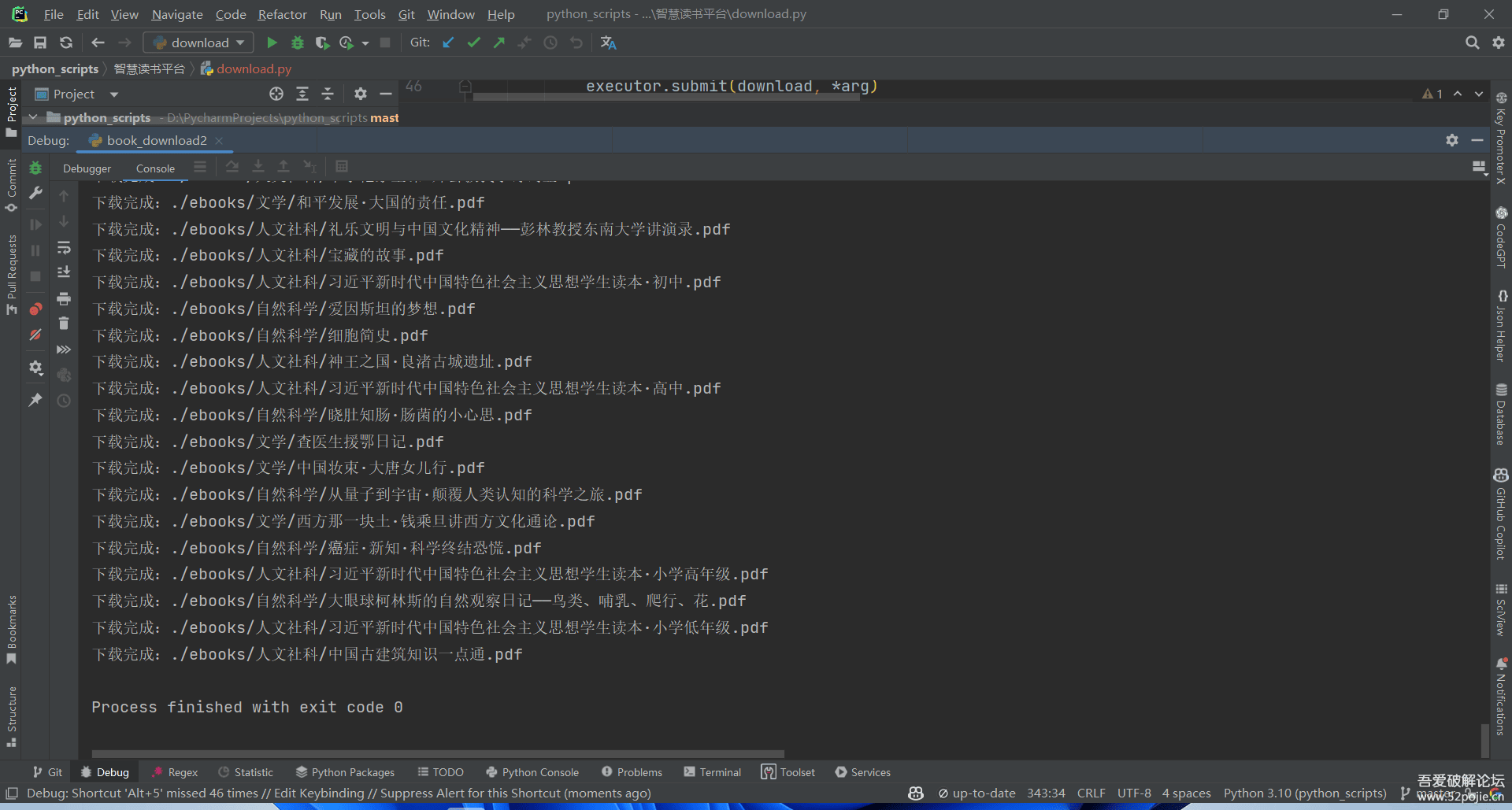
最终全部下载完共计341个文件,文件体积19.1G 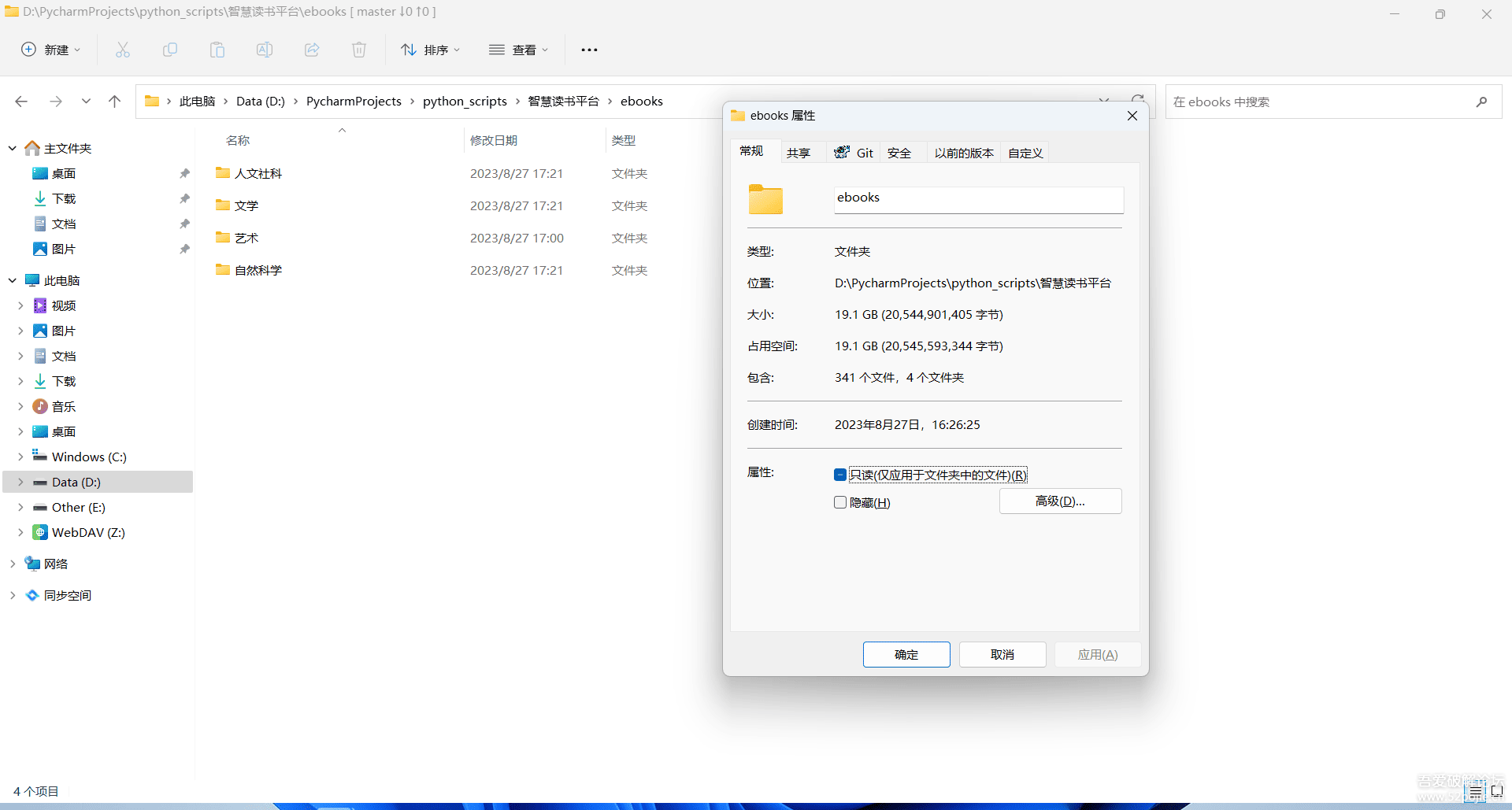
转自52pj大神ameiz其中又4本是无法打开的:鸟与文学,奇泥妙想——纸粘土手工乐园(初级篇),龙兄勇闯古墓,民间美术之旅





评论 (0)